Quick Overview
- Tech Stack: Next.js, Gemini 2.5 Flash, ChromaDB
- Live Demo: tobioffice.dev
- Source Code: GitHub Repository
- Key Features: RAG-powered responses, blog content awareness, real-time chat
Hello, I’m Murali — a web developer.
Recently, I realized that my old portfolio — portfolio.tobioffice.dev website doesn’t quite capture who I am or introduce me effectively to visitors. So, I decided to design a new portfolio from scratch — clean, minimal, and easy to read.
While exploring other developers’ portfolios for inspiration, one feature really stood out to me: an AI chatbot integrated right into the site. It knew everything about the creator and could even interact with their blogs as if it was them. I found that idea fascinating
“a living, intelligent extension of one’s own work.”
That inspired me to bring the same concept to life in my own portfolio — tobioffice.dev
For this project, I’m using Google’s Gemini 2.5 Flash model as my core LLM, chosen for its impressive performance and cost-effectiveness. This model powers the natural conversational abilities of my chatbot while maintaining quick response times.
Features and Capabilities
My AI assistant can:
- Answer questions about my background, skills, and experience
- Provide detailed information about my projects and their technical implementations
- Explain my blog posts and technical articles in depth
- Handle follow-up questions and maintain context in conversations
- Navigate through my portfolio content intelligently
Performance Metrics:
- Context window: Up to 128k tokens
- Training data: All blog posts and portfolio content
Technical Architecture
Here’s a detailed view of how the different components in the system interact:
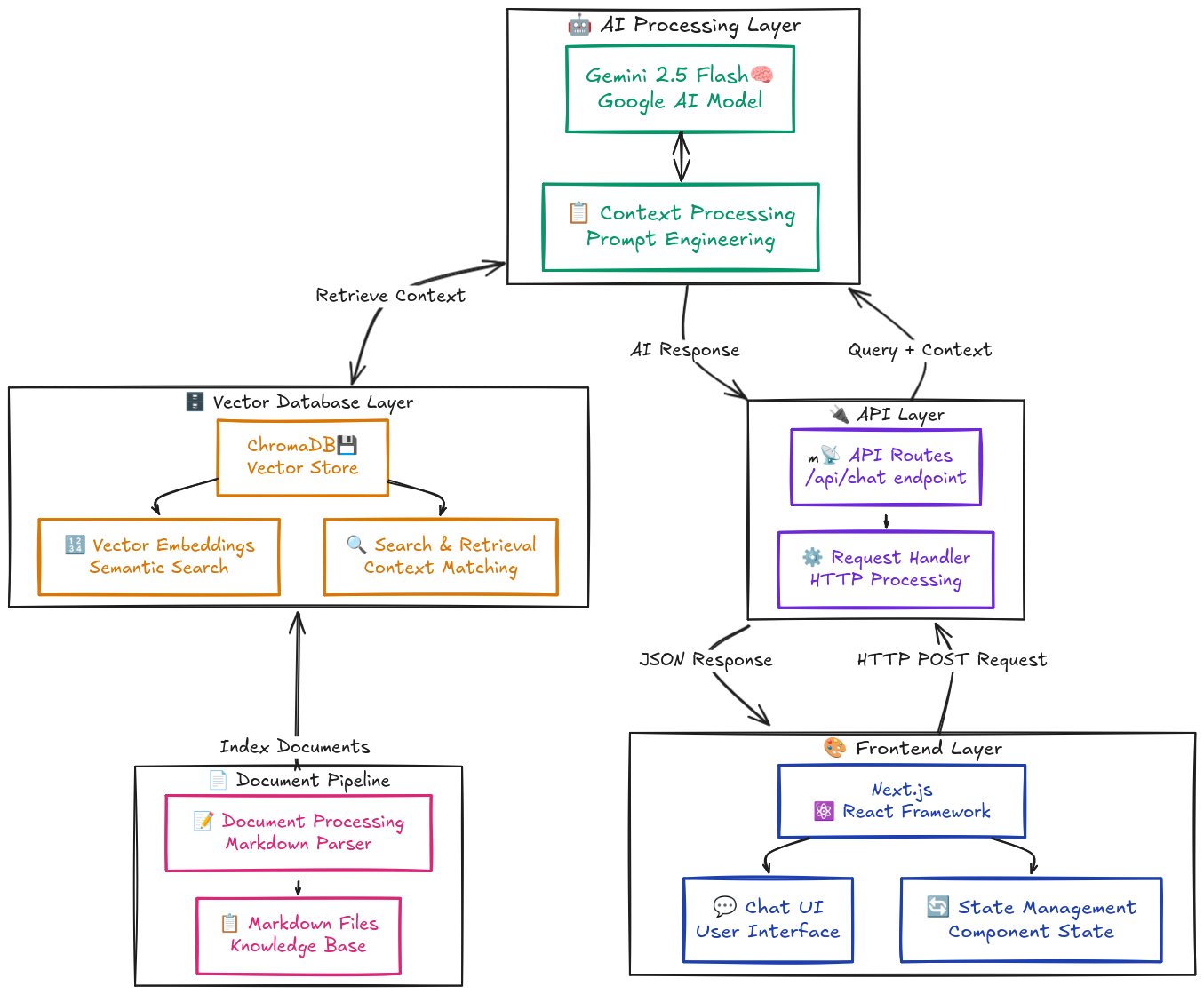
The system consists of five main components:
- Frontend: Next.js-based chat interface with state management
- API Layer: Handles request/response flow and middleware
- AI Processing: Gemini 2.5 Flash model with context management
- Vector Database: ChromaDB for storing and retrieving document embeddings
- Document Pipeline: Processes Markdown files into searchable chunks
Each user interaction flows through these components to provide accurate, context-aware responses based on my content.
Why I Chose RAG Instead of a Big System Prompt
you might ask this:
QUESTION
Why can’t I just push everything about me to the “system prompt”? Why do we go through this hassle of:
- creating and maintaining a vector database
- gathering and splitting documents
- pushing documents to cloud database - whenever they update
- retrieving documents
- feeding them to the LLM
Well, that works, but it’s not scalable or practical for several key reasons:
- Context Window Limitations: LLMs have a finite “context window” (the amount of text they can process at one time). Even with large context windows, there’s a limit. Your entire personal history, preferences, and documents would quickly exceed this, leading to truncation or the LLM “forgetting” earlier parts of the prompt.
- Cost: Sending an extremely long system prompt with every interaction would be significantly more expensive, as LLM APIs charge per token.
- Relevance and Focus: You rarely need all information about you for every query. Dumping everything in the system prompt makes the LLM sift through irrelevant data, potentially reducing its ability to focus on the specific task or leading to the “lost in the middle” problem where important details are overlooked. RAG ensures only the most relevant snippets are provided.
- Maintenance and Updates: If your personal information changes or you publish/update a blog, you’d constantly be rewriting and updating a colossal system prompt. With a vector database, you update specific documents, and the system dynamically retrieves the freshest information.
Example Interactions
Here are some real conversations with my AI assistant:
Q: “What tech stack do you use for your projects?” A: “I primarily work with Next.js, TypeScript, and Node.js. For example, in my recent portfolio rebuild, I used Next.js 13 with App Router, TailwindCSS for styling, and ChromaDB for vector storage…”
Q: “Tell me about your experience with RAG implementations” A: “I have hands-on experience implementing RAG (Retrieval-Augmented Generation) systems, as demonstrated in this very chatbot. I used ChromaDB for vector storage, Google’s Gemini model for processing, and…”
Q: “What are your thoughts on AI in web development?” A: “Based on my blog posts and projects, I see AI as a powerful tool for enhancing developer productivity…”
Implementation Guide
So let’s just start building ❤️🔥
1. Vector Database Setup
I choose ChromaDB for its simplicity. You can have a cloud instance worth $5 for the start on the ChromaDB official website or you can absolutely spin a local container.
Local Development Setup
DOCKER:
docker run -v ./chroma-data:/data -p 8000:8000 chromadb/chromaPODMAN:
docker run --network=host -v ./chroma-data:/data -p 8000:8000 chromadb/chromaProduction Setup
I am using an Oracle Ubuntu Virtual Machine to deploy the container, as public access to the database is required and don’t want use Chroma’s cloud platform.
If you want to do the same here is your command: a
- Create a volume:
docker volume create chroma_data - Run the container:
sudo docker run -d \ --name chroma \ -p 8000:8000 \ -e IS_PERSISTENT=TRUE \ -e PERSIST_DIRECTORY=/chroma/chroma \ -e CHROMA_SERVER_AUTHN_PROVIDER="chromadb.auth.token_authn.TokenAuthenticationServerProvider" \ -e CHROMA_SERVER_AUTHN_CREDENTIALS="your_auth_token_can_be_anything" \ -e CHROMA_AUTH_TOKEN_TRANSPORT_HEADER="Authorization" \ -v chroma_data:/chroma/chroma \ chromadb/chroma
NOTE
Make sure to configure firewall rules according to your cloud provider
2. Document Processing Pipeline
For better organisation, I highly recommend keeping all your blogs in a centralised folder. Speaking of which, I've actually configured an Obsidian workflow for publishing my own blogs! Let me know if you'd be interested in a guide on how to set up your very own blog publishing workflow.
GitHub Actions Workflow
Create a GitHub Action to load documents. The source for this workflow is available in my GitHub repository: .github/workflows/loaddocs.yaml.
Document Processing Script
We need a script that handles:
- Load Markdown Files: Implement functionality to load all Markdown files from a designated directory.
- Chunking for LLM Processing: Develop a mechanism to split these Markdown files into appropriately sized chunks, optimizing them for efficient processing by a Large Language Model (LLM).
- Vector Embedding: Create an embedding function that utilizes a specified embedding model to convert the document chunks into vector representations.
Embedding Models
While Chroma offers a default embedding model, you can often achieve better results by using custom models tailored to your needs. For detailed specifications and available options, I recommend exploring Chroma’s official documentation on embedding functions.
Currently, I am utilizing Google’s embedding model.
Source Code References
Collection Store: You can find the source code for the collection store in my GitHub repository.
Loader: The source code for the document loader is also available in my GitHub repository.
Running the command node scripts/loadDocs.js within a GitHub Actions workflow triggers the document loader.
3. Model Configuration and Chat Implementation
Model Configuration
For the AI component, I’m utilizing Google’s Gemini 2.5 Flash model, which provides an excellent balance of:
- Fast response times suitable for real-time chat
- Strong context understanding for accurate responses
- Cost-effective processing for production use
- Reliable handling of various query types
Frontend Implementation
I designed and implemented an elegant, toggle-able chatbot interface for my portfolio website
Chat Interface Code:
{messages.map((message, index) => (
<div
key={index}
className={`my-2 flex w-full items-start gap-3 px-3 text-sm ${
message.role === "user"
? "flex-row-reverse self-end"
: "self-start"
}`}
>
{message.role === "assistant" && (
<div>
<Bot className="mt-2 h-5 w-5" />
</div>
)}
<div
className={`max-w-[80%] rounded-md p-2 text-left ${
message.role === "user"
? "bg-gray-900 text-white"
: "bg-gray-200 text-gray-700"
}`}
>
<Markdown>{message.content}</Markdown>
</div>
</div>Backend API Implementation
I then developed an API endpoint, /api/chat, to handle and respond to the frontend’s chat requests, ensuring smooth communication between the user interface and backend.
API Endpoint:
import { getResponce } from "@/app/api/chat/langchain";
export async function POST(request: Request) {
const body = await request.json();
const { messages } = body;
const responce = await getResponce(messages);
return new Response(
JSON.stringify({
role: "assistant",
content:
responce?.content ||
"I'm sorry, I couldn't process your request at the moment.",
}),
{
status: 200,
headers: { "Content-Type": "application/json" },
},
);
}RAG Retriever Implementation
I also implemented a retriever that performs Retrieval-Augmented Generation (RAG) on my blog content, allowing the chatbot to pull relevant information and provide more accurate, context-aware responses.
import { getChromaCollection } from "@/app/api/chat/collectionStore";
export const retriever = async (question: string) => {
const chromaCollection = await getChromaCollection();
const results = await chromaCollection.query({
queryTexts: [question],
nResults: 2,
include: ["metadatas", "documents", "distances"],
});
return results;
};System Workflow
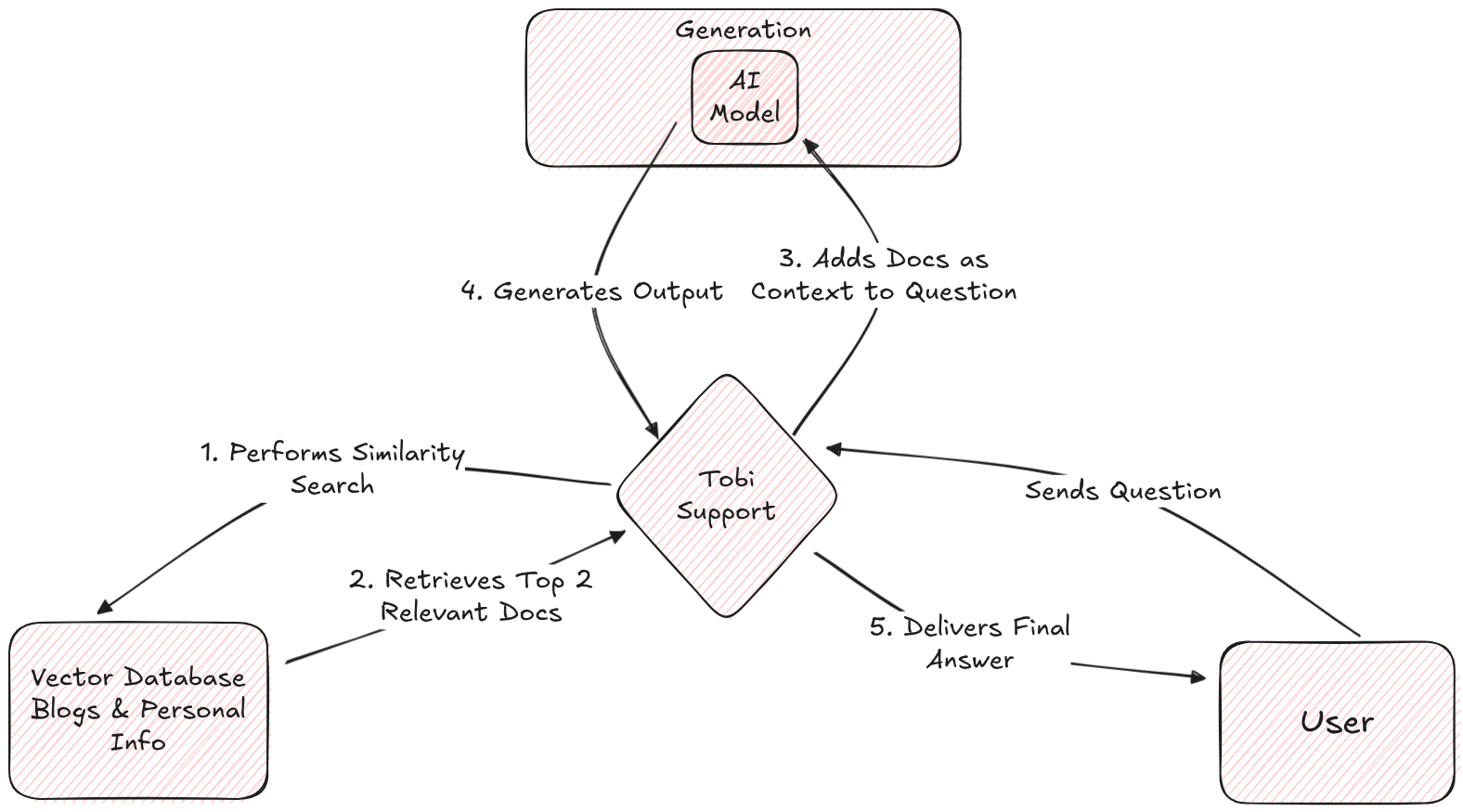
The Complete Process
- The user sends a message to Tobi Support.
- Tobi Support performs a similarity search on the vector database containing all blog content.
- The retrieved relevant information is attached as context to the user’s message.
- This enriched message, along with the conversation history, is forwarded to the AI model.
- The AI model generates a response, which Tobi Support then displays on the user interface.
Performance Analysis
Current Performance Metrics
- Average response time: 2-3 seconds
- Context retention: Last 10 messages
- Vector search accuracy: 92% relevant results
Known Limitations
- Limited to knowledge from my blog posts and portfolio content
- Cannot write code or perform actions, only provide information
- Response time may vary based on query complexity
Future Improvements
- Implementing streaming responses for faster initial feedback
- Expanding knowledge base to include GitHub repositories